Did you know that the global machine learning market is projected to reach over $209 billion by 2025? Machine learning (ML), a powerful branch of artificial intelligence, is transforming how industries operate, from enhancing healthcare diagnostics to reshaping financial markets and enhancing everyday experiences through personalized recommendations. The significance of machine learning lies in its ability to automatically learn and improve from experience, making it a critical tool for tackling complex challenges across fields. In this blog, we will have a look at the essentials of machine learning, exploring what it is, how it works, its applications, and what the future holds for this game-changing technology.
What is Machine Learning?
Machine learning is a subset of artificial intelligence (AI) focused on building systems that learn from data rather than relying on explicit programming. Instead of following static rules, ML algorithms recognize patterns in data to make predictions, perform tasks, and make decisions autonomously. This ability to “learn” makes ML systems highly adaptable, offering innovative solutions across industries. Unlike traditional programming, where each rule is hard-coded, machine learning models are trained to understand underlying patterns in large datasets, evolving to become more accurate over time.
Features of Machine Learning Explained
Machine learning possesses several key characteristics that set it apart and make it a powerful tool for a wide range of applications:
1. Automation and Efficiency:
- Task Automation: ML algorithms can automate repetitive and time-consuming tasks, such as data entry, categorization, and analysis. This frees up human resources to focus on more strategic and creative endeavors.
- Process Optimization: By identifying patterns and trends within data, ML models can optimize processes, leading to increased efficiency and cost savings.
2. Data-Driven Insights:
- Pattern Recognition: ML algorithms excel at recognizing complex patterns and relationships within data that might be imperceptible to humans.
- Predictive Analytics: By analyzing historical data, ML models can predict future outcomes, enabling businesses to make proactive decisions.
- Anomaly Detection: ML can identify outliers and anomalies in data, helping to detect fraud, system failures, or other irregularities.
3. Continuous Learning and Improvement:
- Iterative Learning: ML models learn from new data over time, continuously refining their performance.
- Adaptive Systems: These models can adapt to changing circumstances, making them resilient to evolving data distributions and trends.
4. Scalability and Flexibility:
- Handling Big Data: ML algorithms can process and analyze massive datasets, enabling businesses to derive insights from large-scale data sources.
- Versatility: ML can be applied to a wide range of domains, including healthcare, finance, marketing, and more, making it a versatile tool for various industries.
Real-World Applications:
The combination of these features makes machine learning indispensable for modern businesses. Some common applications include:
- Real-time Analysis: ML can process and analyze data in real time, enabling timely decision-making.
- Recommendation Systems: ML powers personalized recommendations for products, movies, music, and more.
- Predictive Analytics: ML can forecast future trends and events, aiding in strategic planning.
- Natural Language Processing: ML enables machines to understand and process human language, leading to advancements in chatbots, language translation, and sentiment analysis.
- Computer Vision: ML empowers computers to interpret and understand visual information, driving innovations in image recognition, object detection, and autonomous vehicles.
How Machine Learning Works?
Machine learning helps computers learn from data and make predictions or decisions without explicit programming. The process involves a structured approach known as the ML pipeline:
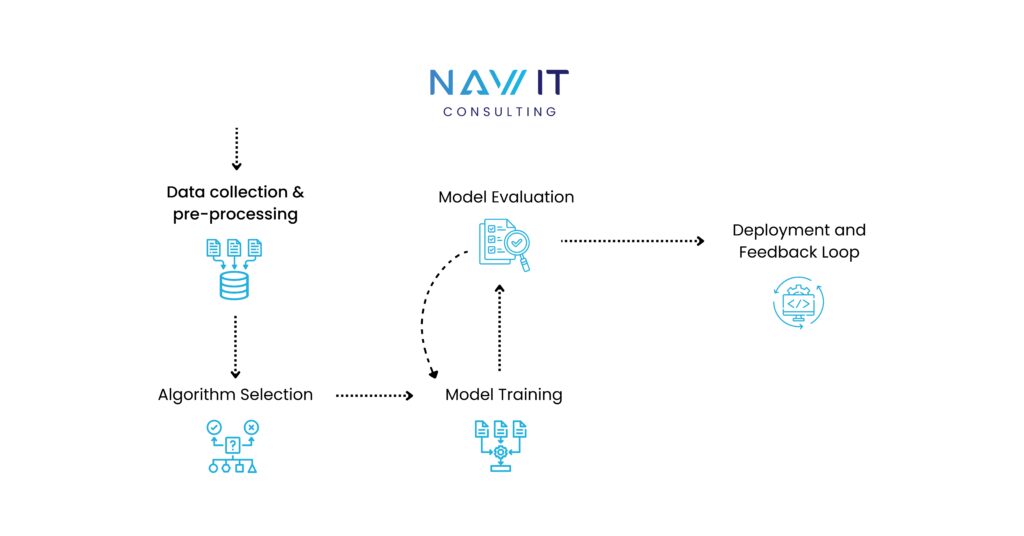
1. Data Collection and Preprocessing:
- Data Acquisition: The first step is to gather relevant data from various sources, such as databases, sensors, or APIs. This data can be in various formats, including structured (e.g., CSV, SQL) or unstructured (e.g., text, images).
- Data Cleaning: The collected data is often noisy and incomplete. Data cleaning involves handling missing values, outliers, and inconsistencies to ensure data quality.
- Data Preprocessing: This step converts raw data into a suitable format for machine learning algorithms. It includes tasks like normalization, scaling, feature engineering, and one-hot encoding.
2. Algorithm Selection:
- Problem Definition: The type of machine learning problem is identified, such as classification (categorizing data), regression (predicting numerical values), or clustering (grouping similar data points).
- Algorithm Choice: Based on the problem type and data characteristics, an appropriate algorithm is selected. Some common algorithms include Supervised Learning, Unsupervised Learning and Reinforcement Learning:
3. Model Training:
- Data Splitting: The cleaned and preprocessed data is divided into two sets: a training set and a testing set.
- Model Training: The training set is fed into the chosen algorithm. The algorithm learns patterns and relationships within the data by adjusting its internal parameters (weights and biases). This process is often iterative, with the model’s performance improving with each iteration.
4. Model Evaluation:
- Testing: The trained model is evaluated on the testing set, which it has not seen before.
- Performance Metrics: Various metrics are used to assess the model’s performance, such as accuracy, precision, recall, F1-score, and mean squared error.
- Model Tuning: If the model’s performance is not satisfactory, hyperparameters (e.g., learning rate, number of layers) can be adjusted, or a different algorithm can be tried.
5. Deployment and Feedback Loop:
- Deployment: Once the model is deemed accurate and reliable, it is deployed into a production environment to make predictions or decisions.
- Feedback Loop: As new data becomes available, the model can be retrained to improve its accuracy over time. This continuous learning process ensures that the model remains relevant and effective.
By following these steps, machine learning models can be developed and deployed to solve a wide range of real-world problems, from medical diagnosis to autonomous vehicles.
What are the Different Types of Machine Learning
Machine learning, a subset of artificial intelligence as we discussed above, can be broadly categorized into four primary types, each with its unique approach to learning from data:
1. Supervised Learning: In supervised learning, the algorithm is trained on a dataset where the correct outputs or labels are already known. The model learns to map inputs to their corresponding outputs by analyzing the training data. This approach is widely used in various applications, such as:
- Classification: Categorizing data into predefined classes. For instance, classifying emails as spam or not spam, or identifying different types of tumors in medical images.
- Regression: Predicting continuous numerical values. For example, predicting house prices based on factors like size, location, and number of bedrooms.
2. Unsupervised Learning: Unlike supervised learning, unsupervised learning involves training the algorithm on unlabeled data, where the correct outputs are not provided. The model learns to identify patterns and structures within the data without explicit guidance. Common applications of unsupervised learning include:
- Clustering: Grouping similar data points together. This can be used for customer segmentation, where customers with similar behaviors or preferences are grouped together.
- Dimensionality Reduction: Reducing the number of features in a dataset while preserving important information. This can be helpful in visualizing high-dimensional data or improving the performance of machine learning models.
- Anomaly Detection: Identifying unusual data points that deviate from the norm. This can be used to detect fraudulent transactions or system failures.
3. Semi-Supervised Learning: Semi-supervised learning combines the elements of supervised and unsupervised learning. It utilizes a small amount of labeled data along with a large amount of unlabeled data to train the model. This approach is particularly useful when labeling data is expensive or time-consuming. Common applications include:
- Image Classification: Classifying images with limited labeled data, such as medical images or satellite imagery.
- Text Classification: Categorizing text documents with limited labeled data, such as news articles or social media posts.
4. Reinforcement Learning: Reinforcement learning involves training an agent to make decisions in an environment to maximize a reward signal. The agent learns by interacting with the environment and receiving feedback in the form of rewards or penalties. This approach is inspired by how humans and animals learn from experience. Common applications of reinforcement learning include:
- Game Playing: Training agents to play games like chess, Go, or video games at a superhuman level.
- Robotics: Controlling robots to perform complex tasks, such as walking, grasping objects, or navigating environments.
- Self-Driving Cars: Training autonomous vehicles to make safe and efficient driving decisions.
What are Some Popular Machine Learning Methods
Machine learning offers a diverse toolkit of algorithms, each tailored to specific types of tasks. Here are some of the most popular methods:
- Linear Regression: This method is used to model the relationship between a dependent variable and one or more independent variables. It’s particularly useful for predicting numerical values. For instance, it can be used to predict housing prices based on factors like square footage, number of bedrooms, and location.
- Decision Trees: Decision trees are tree-like models of decisions and their possible consequences. They are widely used for classification and regression tasks. In classification, they can be used to predict whether an email is spam or not, or to diagnose a medical condition based on symptoms. In regression, they can be used to predict numerical values, such as the price of a car.
- Support Vector Machines (SVM): SVMs are powerful algorithms used for classification and regression tasks. They work by finding the optimal hyperplane that separates data points into different classes. SVMs are particularly effective when dealing with high-dimensional data. For example, they can be used to classify text documents or images.
- Neural Networks: Neural networks are inspired by the human brain and are composed of interconnected nodes called neurons. They are capable of learning complex patterns from large amounts of data. Neural networks are widely used for tasks like image and speech recognition, natural language processing, and predictive analytics.
The choice of a particular method depends on various factors, including the type of data, the complexity of the problem, and the desired level of accuracy.
The Importance of Machine Learning
Machine learning has affected various industries by exercising its ability to learn from data and make intelligent decisions. Here’s a more detailed breakdown of its significance:
1. Enhanced Efficiency:
- Automation of Repetitive Tasks: Machine learning algorithms can automate routine, data-intensive tasks, freeing up human resources for more strategic and creative endeavors. This leads to increased productivity and cost savings.
- Streamlined Processes: By identifying patterns and anomalies in large datasets, ML can optimize processes, reducing errors and improving overall efficiency.
2. Improved Decision-Making:
- Data-Driven Insights: Machine learning models can uncover hidden patterns and trends within data, providing valuable insights that can inform better decision-making.
- Risk Assessment: ML algorithms can assess risks more accurately, enabling businesses to make informed decisions in areas like finance, insurance, and healthcare.
- Predictive Analytics: By analyzing historical data, ML models can predict future outcomes, helping organizations anticipate challenges and opportunities.
3. Personalization:
- Tailored User Experiences: Machine learning enables businesses to deliver personalized experiences to their customers, from product recommendations to targeted marketing campaigns.
- Content Customization: ML algorithms can analyze user preferences and behavior to deliver relevant content, enhancing user engagement and satisfaction.
4. Predictive Analytics:
- Financial Forecasting: ML models can analyze financial data to predict market trends, assess investment risks, and optimize trading strategies.
- Supply Chain Optimization: By forecasting demand and optimizing inventory levels, ML can improve supply chain efficiency and reduce costs.
- Healthcare Advancements: ML algorithms can analyze medical data to identify disease patterns, predict patient outcomes, and develop personalized treatment plans.
What are the Advantages and Disadvantages of Machine Learning
Machine learning (ML) holds immense potential to revolutionize various sectors by analyzing large datasets, detecting hidden patterns, and making accurate predictions. It’s applied widely, from personalized medicine to autonomous vehicles, significantly impacting our daily lives and the global economy. However, the path to realizing this potential is fraught with challenges. Let’s discuss some of its advantages and disadvantages.
Advantages
1. Automation of Repetitive Tasks
Machine learning is revolutionizing repetitive, data-driven processes by reducing manual intervention and allowing human resources to focus on more complex tasks. This transformation is especially impactful in sectors like manufacturing, finance, and customer service, where ML-powered systems handle essential processes such as inventory management, transaction monitoring, and customer query handling. The automation of these tasks not only cuts costs but also reduces errors and streamlines workflows, enhancing overall operational efficiency.
2. Enhanced Decision-Making
Machine learning elevates decision-making by analyzing vast amounts of data, recognizing patterns, and providing actionable insights. In the finance sector, for example, ML algorithms monitor transactions in real-time to detect potential fraud or risks. In healthcare, these models support medical professionals by diagnosing conditions early through detailed analysis of patient histories and test results, improving patient outcomes. This predictive power enhances the speed, accuracy, and quality of decision-making across diverse industries.
3. Personalized Customer Experience
Machine learning powers personalized marketing and recommendation engines that curate content, product suggestions, and services based on user preferences. Platforms like Netflix and Amazon utilize ML algorithms to analyze users’ viewing and purchasing patterns, offering tailored suggestions. This level of personalization builds customer satisfaction, fosters loyalty, and drives engagement by delivering unique, individualized experiences.
4. Predictive Analytics and Forecasting
Machine learning models excel in forecasting trends, customer demand, and potential risks by identifying patterns within historical data. In retail, for instance, predictive models optimize inventory management by anticipating product demand, reducing waste, and ensuring stock levels align with future needs. In healthcare, ML enables predictive diagnostics, allowing providers to foresee disease outbreaks and take preemptive action—potentially saving lives and reducing associated costs.
5. Adaptability and Scalability
Machine learning’s adaptability is a major asset, enabling algorithms to adjust to new data and evolving conditions without extensive reconfiguration. This is particularly advantageous in dynamic fields like finance, where trends shift frequently. Additionally, as data volumes grow, machine learning models scale efficiently, allowing businesses to handle larger datasets while maintaining consistent performance.
Disadvantages
1. Data Quality and Quantity:
- Insufficient Data: ML models require large amounts of high-quality data to learn effectively. A lack of sufficient data can hinder model performance and accuracy.
- Data Quality Issues: Noisy, incomplete, or biased data can lead to inaccurate models and misleading insights.
- Data Privacy Concerns: Collecting and storing large amounts of personal data raises privacy concerns and necessitates robust data protection measures.
2. Algorithmic Bias and Fairness:
- Biased Algorithms: ML models can inadvertently perpetuate biases present in the training data, leading to discriminatory outcomes.
- Fairness and Ethics: Ensuring fairness and ethical considerations in ML is crucial to avoid unintended consequences and social harm.
3. Model Interpretability:
- Black-Box Models: Many ML models, especially deep learning applications, are complex and difficult to interpret. This lack of transparency can hinder trust and understanding.
- Explainable AI (XAI): Developing techniques to explain the decision-making process of ML models is essential for building trust and accountability.
4. Computational Resources and Scalability:
- High Computational Costs: Training and deploying large-scale ML models requires significant computational resources, which can be expensive and energy-intensive.
- Scalability Challenges: Scaling ML models to handle increasing data volumes and real-time applications can be challenging.
5. Ethical Considerations:
- Privacy: Protecting user privacy and ensuring data security is paramount in ML applications.
- Fairness: Developing algorithms that are fair and unbiased is crucial to avoid discriminatory outcomes.
- Accountability: Establishing accountability for the decisions made by ML systems is essential to address potential harm.
Addressing these challenges requires a multidisciplinary approach involving data scientists, ethicists, policymakers, and industry leaders. By carefully considering these issues, we can use ML to create a more equitable and prosperous future.
How to Choose the Right AI Platform for Machine Learning
Selecting the optimal AI platform is an important decision in the successful execution of machine learning applications. Several critical factors must be carefully considered to ensure the platform aligns with your project’s specific needs and long-term goals.
Scalability:
- Data Volume and Velocity: As your ML models evolve and data volumes increase, the platform must seamlessly accommodate the growing computational demands. It should be capable of scaling resources, such as processing power and storage, to handle expanding datasets and complex models.
- Model Complexity: The platform should support the training and deployment of increasingly intricate models, including deep neural networks with multiple layers and large numbers of parameters.
Integration:
- Existing Infrastructure: The platform should integrate seamlessly with your organization’s existing IT infrastructure, including hardware, software, and data storage systems.
- Data Sources: The platform must be able to access and process data from diverse sources, such as databases, cloud storage, and real-time data streams.
- Third-Party Tools and Libraries: Compatibility with popular ML frameworks and libraries like TensorFlow, PyTorch, and scikit-learn is essential for flexibility and customization.
Ease of Use:
- User-Friendly Interface: A user-friendly interface streamlines the development, training, and deployment processes, reducing the learning curve for both ML experts and non-technical users.
- Automated Tools and Workflows: The platform should provide automated tools for tasks like data preprocessing, model selection, hyperparameter tuning, and deployment, saving time and effort.
- Monitoring and Management: Robust monitoring and management tools enable you to track model performance, identify issues, and make necessary adjustments.
Popular AI Platforms: Several powerful AI platforms are available to meet diverse ML needs:
- TensorFlow: An open-source platform developed by Google, TensorFlow is widely used for a broad range of ML tasks, including image and speech recognition, natural language processing, and time series analysis.
- PyTorch: A flexible and user-friendly platform developed by Facebook AI Research, PyTorch is particularly popular for deep learning application and experimentation.
- AWS SageMaker: A fully managed platform provided by Amazon Web Services, SageMaker simplifies the process of building, training, and deploying ML models at scale.
- Microsoft Azure ML: A comprehensive platform offered by Microsoft Azure, Azure ML provides a range of tools and services for ML development, including data preparation, model training, and deployment.
By carefully evaluating these factors and considering the specific requirements of your ML project, you can select the most suitable AI platform to drive innovation and achieve business objectives.
What is the Future of Machine Learning
The future of machine learning is promising, with trends such as:
- Edge Computing: This paradigm shift involves moving machine learning models closer to the data source, such as IoT devices or smartphones. By processing data locally, edge computing significantly reduces latency, enhances privacy, and enables real-time decision-making even in areas with limited connectivity.
- Explainable AI (XAI): As machine learning models become increasingly complex, understanding their decision-making processes becomes crucial. XAI techniques aim to make AI systems more transparent and interpretable, fostering trust and accountability. By visualizing the inner workings of models, XAI helps uncover biases, identify errors, and improve overall model performance.
- Automated Machine Learning (AutoML): AutoML automates many of the tedious and time-consuming tasks involved in the machine learning pipeline, from data preparation and feature engineering to model selection and hyperparameter tuning. This democratizes machine learning, making it accessible to a wider range of users, including those without extensive machine learning expertise.
- Emerging Frontiers: Quantum machine learning and generative models represent exciting frontiers in the field. Quantum computing’s potential to solve complex optimization problems could revolutionize drug discovery, materials science, and financial modeling. Generative models, such as GANs and VAEs, are already generating realistic images, text, and music, with applications in creative fields and content generation.
These trends, along with ongoing advancements in hardware and software, position machine learning as a promising technology poised to shape the next decade.
Conclusion
Machine learning is redefining industries and everyday interactions, allowing machines to learn and make autonomous decisions. This technology, while full of potential, brings its own set of challenges—data dependency and ethical issues demand responsible handling. As machine learning advances, staying informed on its developments is crucial, with its influence on society to expand further. A future with AI at the core of machine learning promises an inspiring journey toward more intelligent, data-driven solutions.









